Notes on Searching the Digitized Uzbek National Bibliography
General notes on searching the documents:
There are two layers to each document. The top layer (what you see) is the image of the original scan.
The bottom layer (which you don’t see) is the searchable characters. The top layer and the bottom
layer don’t always match perfectly. If you see a word, but can’t find it when searching, this is an
example of a mismatch between the layers.
Because there is sometimes a mismatch between the layers, these documents are best suited to keyword
searches – i.e. to finding out most of what has been published on a particular topic. They are not
well suited to use as a corpus (counting the exact number of time a word appears).
In some cases, the top and the bottom layer may not be aligned. If you copy and paste a word from the PDF,
but you only get part of the word, or if you copy and paste a word, but get the word next to it, these
are examples of how the text may not be perfectly aligned. This should not affect searching.
Russian words will be found with more accuracy than Uzbek words
Uzbek words will be found with more accuracy than Kyrgyz, Kazakh, and Karakalpak words
Uzbek Cyrillic words will be found with more accuracy than Uzbek and other Latin words (
in the 1928-1930,
1932, 1937-1940 documents only; for tips for searching these documents, see "Tips for Searching Latin Uzbek"
).
The following characters are not differentiated:
ў у Й И Ё Е
This means that a search for Ё will bring up results for both Ё and Е and so on.
Most hyphenated words that appear at line breaks will be searchable (i.e. "респу-блика" will be found by searching
for "республика"). However, there are a few cases where hyphenated words have been misrecognized and will not be found.
Portions of some documents are from bad quality scans which may not be searchable. Slightly (very slightly)
better quality scans are available if you request them from library staff. However, these are not searchable.
In addition to these general notes, there are also specific things to be aware of concerning the different
"fonts" in our database of PDFs. For information about the peculiarities of these fonts, see below.
Notes for the 1946-1961, 1978-1992, end of 1998-2000 documents and all of the Kitob Sovet Uzbekistana Kitobi documents:
In addition to the general issues outlined above, the biggest issue here is the confusion between "И" and "Н".
We highly recommend searching with both characters. For example, if you want to find the word "ишлаш" search
for both "ишлаш" and "ншлаш". This may results in additional results.
The following characters are also confused with one another; however, the problem here is not as bad as the
confusion between И and Н. If feasible, we recommend searching with both characters for the following pairs as well:
Қ К Ҳ Х Ғ Г
Notes on Uzbek Latin text in the 1928-1930, 1932, 1937-1940 documents:
Bibliographies from these years use Latin rather than Cyrillic characters. The Latin alphabet used, however, differs
significantly from the modern Uzbek Latin alphabet, as do spelling conventions. The following chart compares the
Uzbek Latin alphabet of this period with modern Uzbek Latin:
Modern
Old
Unicode
A a
A a
Ə ə
018F 0259
B b
B ʙ*
D d
D d
E e
E e
F f
F f
G g
G g
H h
H h
I i
I i
Ь ь**
J j
Ç ç
00C7 00E7
Ƶ ƶ
01B5 01B6
K k
K k
Modern
Old
Unicode
L l
L l
M m
M m
N n
N n
O o
O o
Ɵ ɵ
019F 0275
P p
P p
Q q
Q q
R r
R r
S s
S s
T t
T t
U u
U u
V v
V v
X x
X x
Modern
Old
Unicode
Y y
J j
Z z
Z z
O’ o’
O o
G’ g’
Ƣ ƣ
01A2 01A3
Sh sh
Ş ş
015E 015F
Ch ch
C c
Ng ng
Ŋ ŋ
014A 014B***
‘
‘
Ye ye
Ye ye
Yo yo
Yo yo
Yu yu
Yu yu
Ya ya
Ya ya
Ts ts
Ts ts
*All occurrences of lowercase ʙ appear in the scanned documents as uppercase B.
**This character is recognized in the documents as I i, or not recognized at all. Try I i in your searches and/or try omitting the character completely.
NOTE: Some of these documents also contain Tajik, Kazak, and other Latin alphabets
Tips for Searching Uzbek Latin Portions of the Text:
Spelling in these portions of the documents is inconsistent and differs significantly from modern Uzbek spelling.
You may search Uzbek Latin portion of the text using your keyboard and the additional special characters available
through the onscreen keyboard at the top right hand of the page
If your search for a particular term returns no results, try alternate spellings, especially alternative vowels.
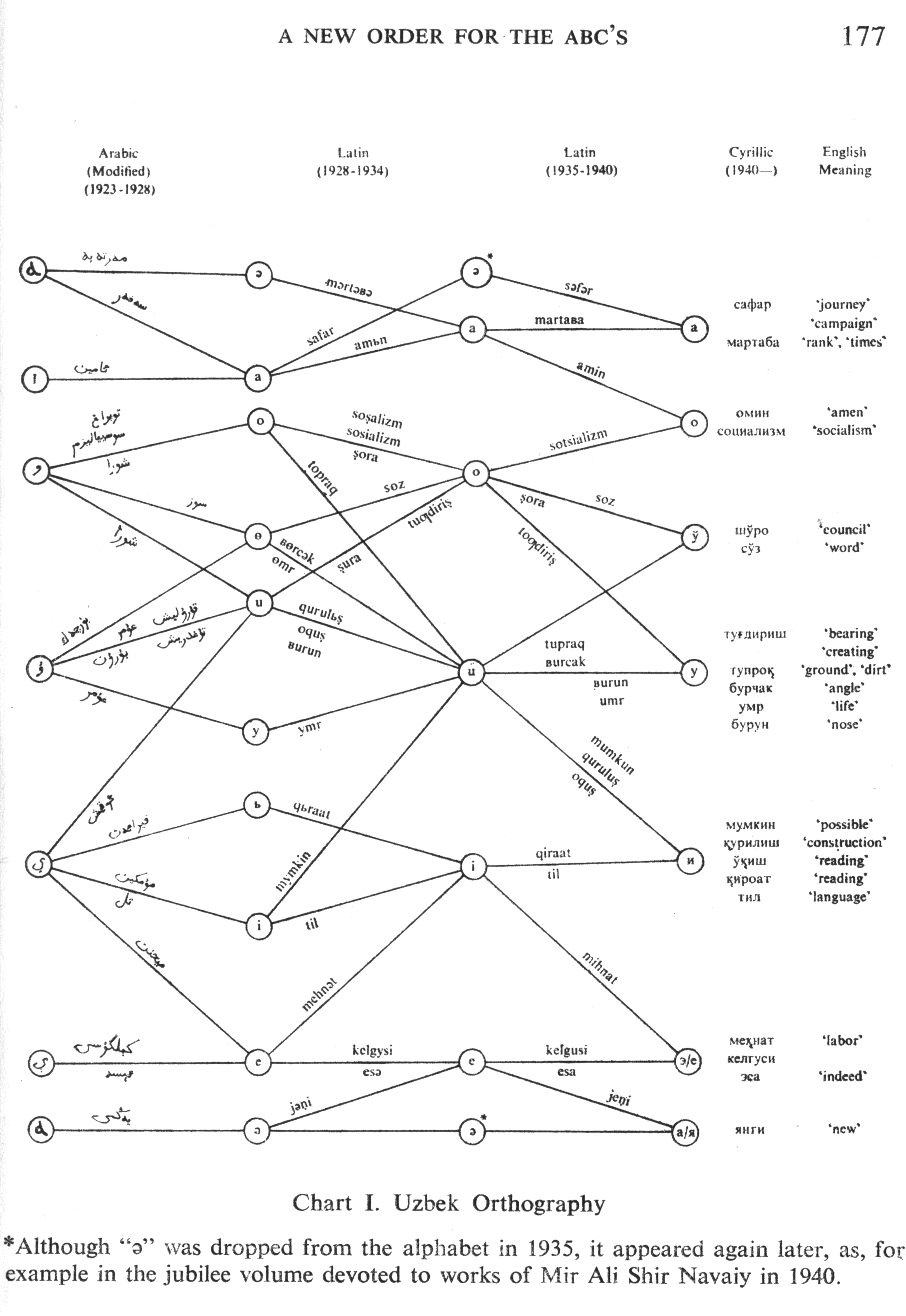
To learn more about vowel usage in Latin Uzbek of this period, consult the chart below:
Source: Allworth, Edward, Uzbek Literary Politics. The Hague: Mouton, 1964.
Note:
The vowels Ə ə and Ɵ ɵ appear in some documents, but are not recognized. They may be recognized as A a and O o, respectively,
but recognition is inconsistent.
A character that resembles a Cyrillic soft sign (ь) appears occasionally to represent I i. This character is not recognized.
If you fail to a find word with an I i sound, try omitting that character and searching again.
Modern Uzbek J j are represented in the text as both Ç ç and Ƶ ƶ. The latter is used primarily in Russian words to represent Cyrillic Ж ж.
The "ng" sound occurs in the texts alternately as N̡ ᶇ and Ng ng.
The characters 1, I, and i are often improperly recognized and confused. Try alternate spellings.
Words that in modern Latin Uzbek, are spelled with O o are often spelled with A a in the documents (ex. modern "Bola" is spelled
"Bala"; modern "Ost" is spelled "Ast"; modern "Oltin" is spelled "Altin").